|
|
|
|
|
|
|
|
|
|
|
|
|
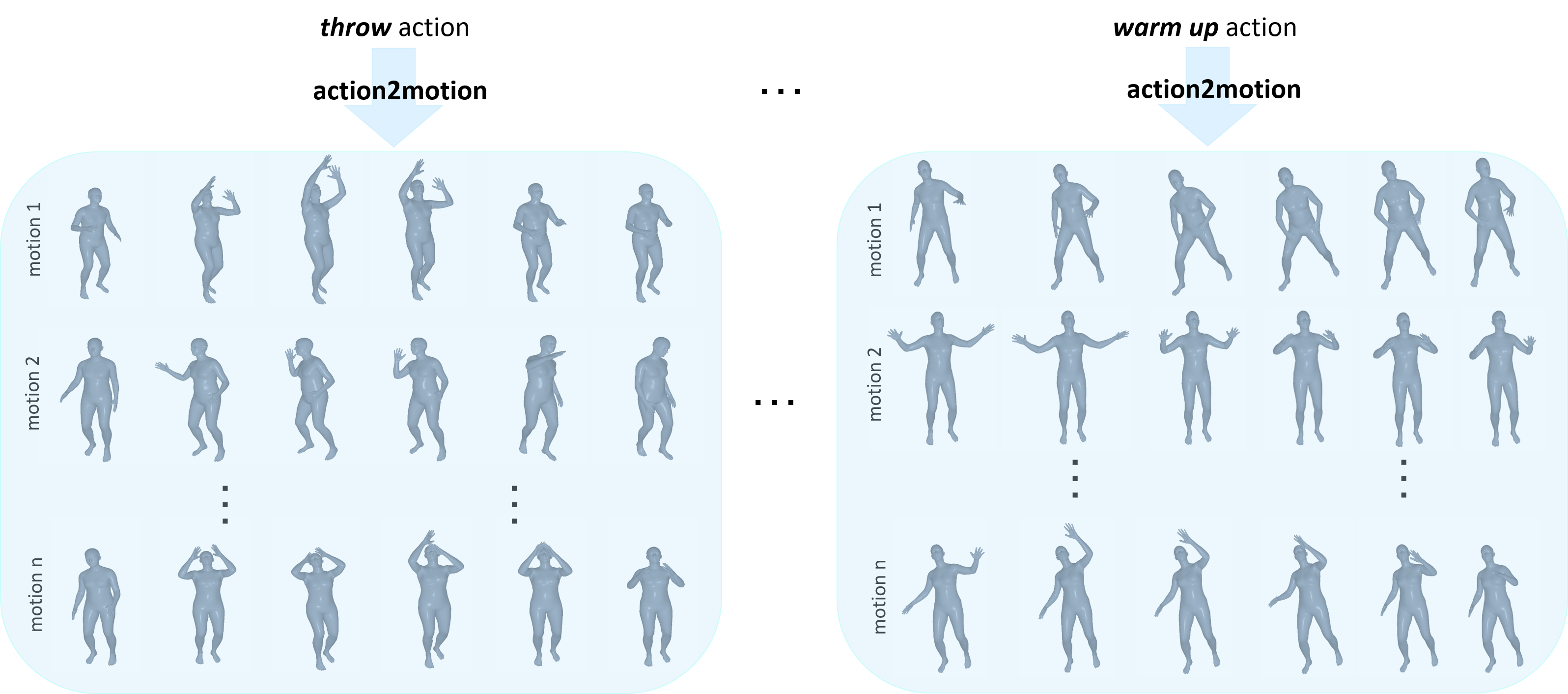 |
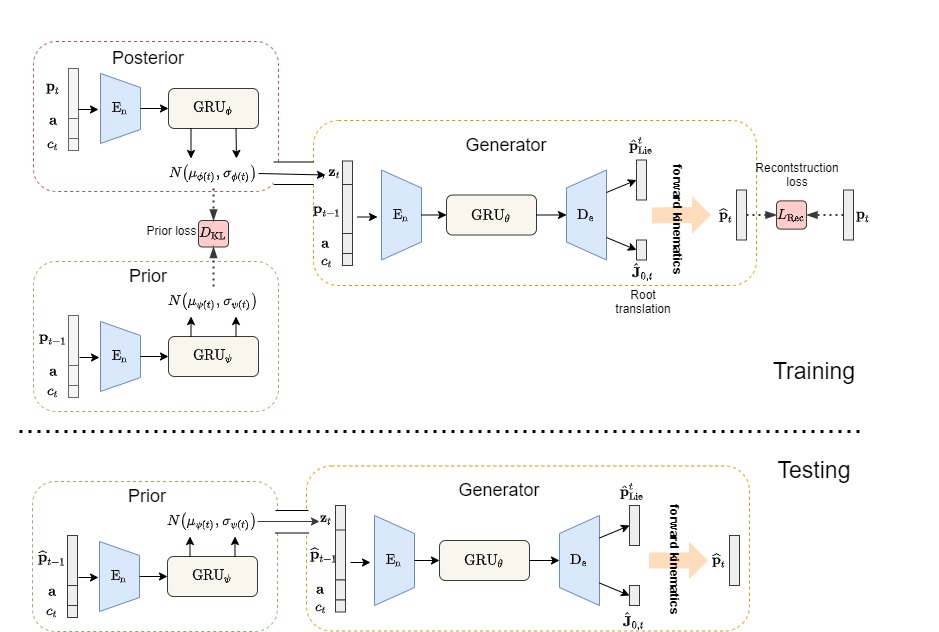
Action recognition is a relatively established task, where given an input sequence of human motion, the goal is to predict its action category. This paper, on the other hand, considers a relatively new problem, which could be thought of as an inverse of action recognition: given a prescribed action type, we aim to generate plausible human motion sequences in 3D. Importantly, the set of generated motions are expected to maintain its diversity to be able to explore the entire action-conditioned motion space; meanwhile, each sampled sequence faithfully resembles a natural human body articulation dynamics. Motivated by these objectives, we follow the physics law of human kinematics by adopting the Lie Algebra theory to represent the natural human motions; we also propose a temporal Variational Auto-Encoder (VAE) that encourages a diverse sampling of the motion space. A new 3D human motion dataset, HumanAct12, is also constructed. Empirical experiments over three distinct human motion datasets (including ours) demonstrate the effectiveness of our approach.
 |
Action2Motion: Conditioned Generation of 3D Human Motions Chuan Guo, Xinxin Zuo, Sen Wang, Shihao Zou, Qingyao Sun, Annan Deng, Minglun Gong, Li Cheng ACM MultiMedia, 2020 [Paper] [Bibtex] |
Demo Video
|
|
Data
|
HumanAct12 is adopted from the polar image and 3D pose dataset PHSPD, with proper temporal cropping and action annotating. Statistically, there are 1191 3D motion clips(and 90,099 poses in total) which are categorized into 12 action classes, and 34 fine-grained sub-classes. The action types includes our daily actions such as walk, run, sit down, jump up, warm up, etc. Fine-grained action types contain more specifical information like Warm up by bowing left side, Warm up by pressing left leg, etc. The detailed statistics of HumanAct12 could be referred to our paper or documents in the dataset link. Our dataset also is registered with PHSPD dataset, in case one also needs extra meta-source(e.g. polar image, depth image, color image, etc); please see the ReadMe file for detailed registration information. If you're only intereted in 3d joints and action annoataion of human motion, you could just download our dataset here. If you require more dedicated data modality, you may consider PHSPD as well. |
|
Due to the inaccuracy of 3D joint annoations in original NTU-RGBD dataset, we re-estimate the 3D positions of poses from the point cloud extratcted from rough RGBD videos, by the recently proposed method "video inference for human body pose and shape estimation(CVPR 2020)" . Note this dataset is only partial of NTU-RGBD dataset, which contains 13 distinct acition types(e.g. cheer up, pick up, salute, etc.) constituting 3,902 motion clips. We kept the name of each motion as origin. Due to the Release Agreement of NTU-RGBD dataset, we are not allowed to and will no longer provide the access to our re-estimated NTU-RGBD data. |
|
The original CMU Mocap dataset is not orgnized by action types. Based on their motion descriptions, we identify 8 disparate actions, including running, walking, jumping, climbing, and manually re-organize 1,088 motions. Here each skeleton is annotated with 20 3D joints (19 bones). In practice, the pose sequences are down-sampled to a frequency of 12 HZ from 100 HZ. Download here |
Visual Results
Phone |

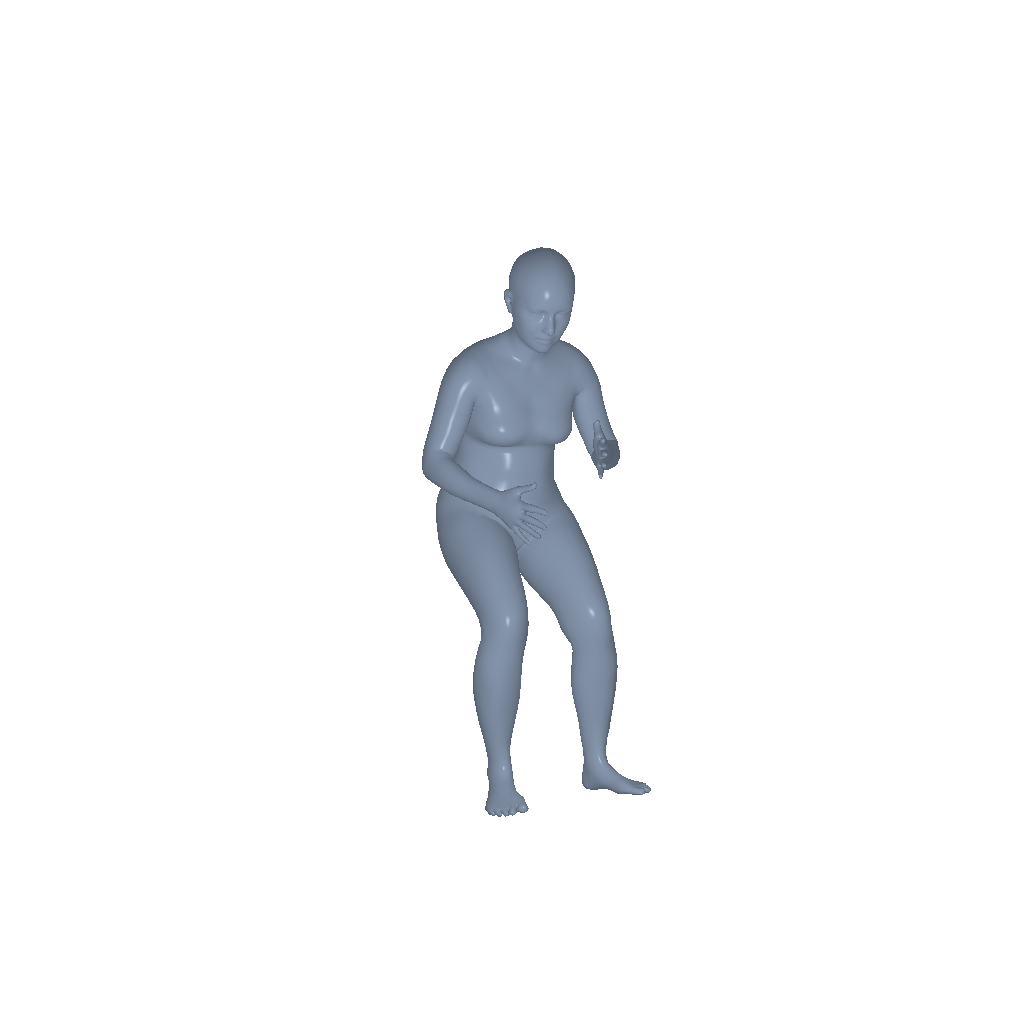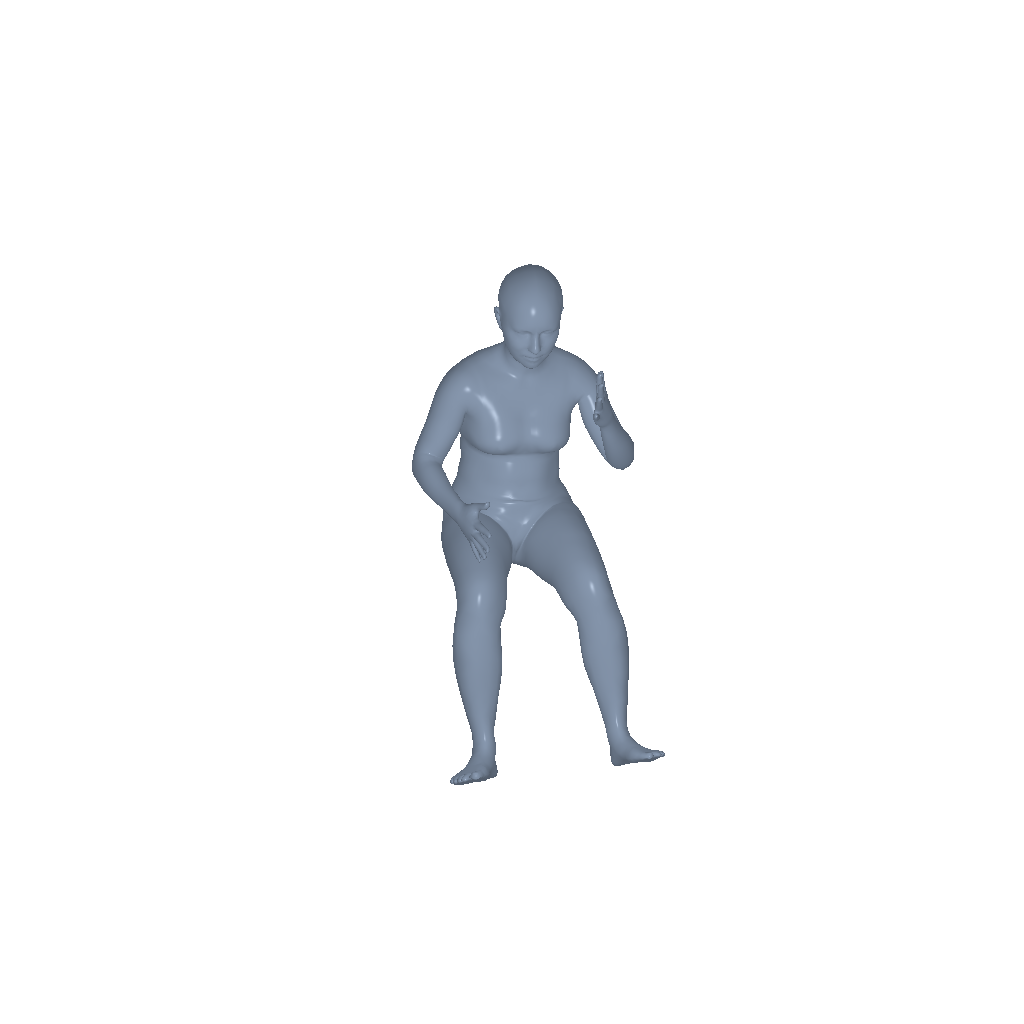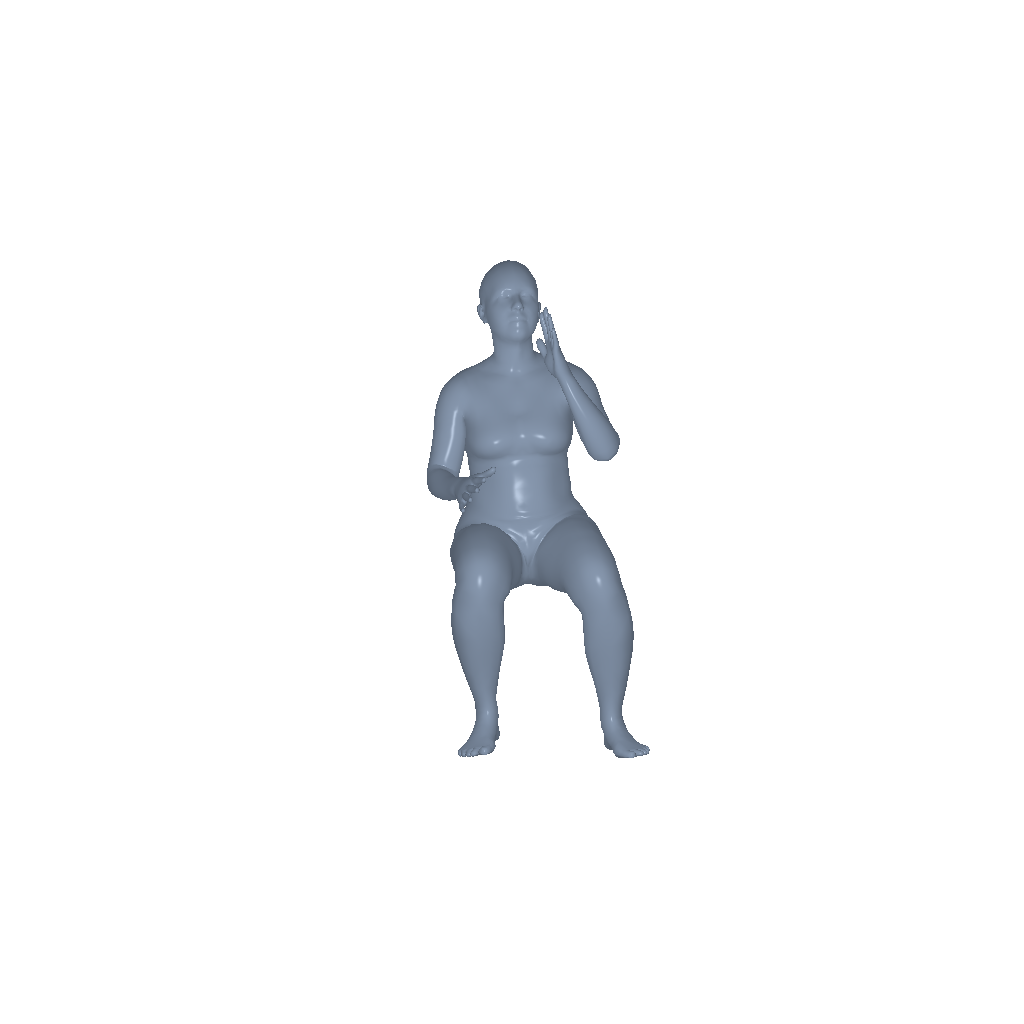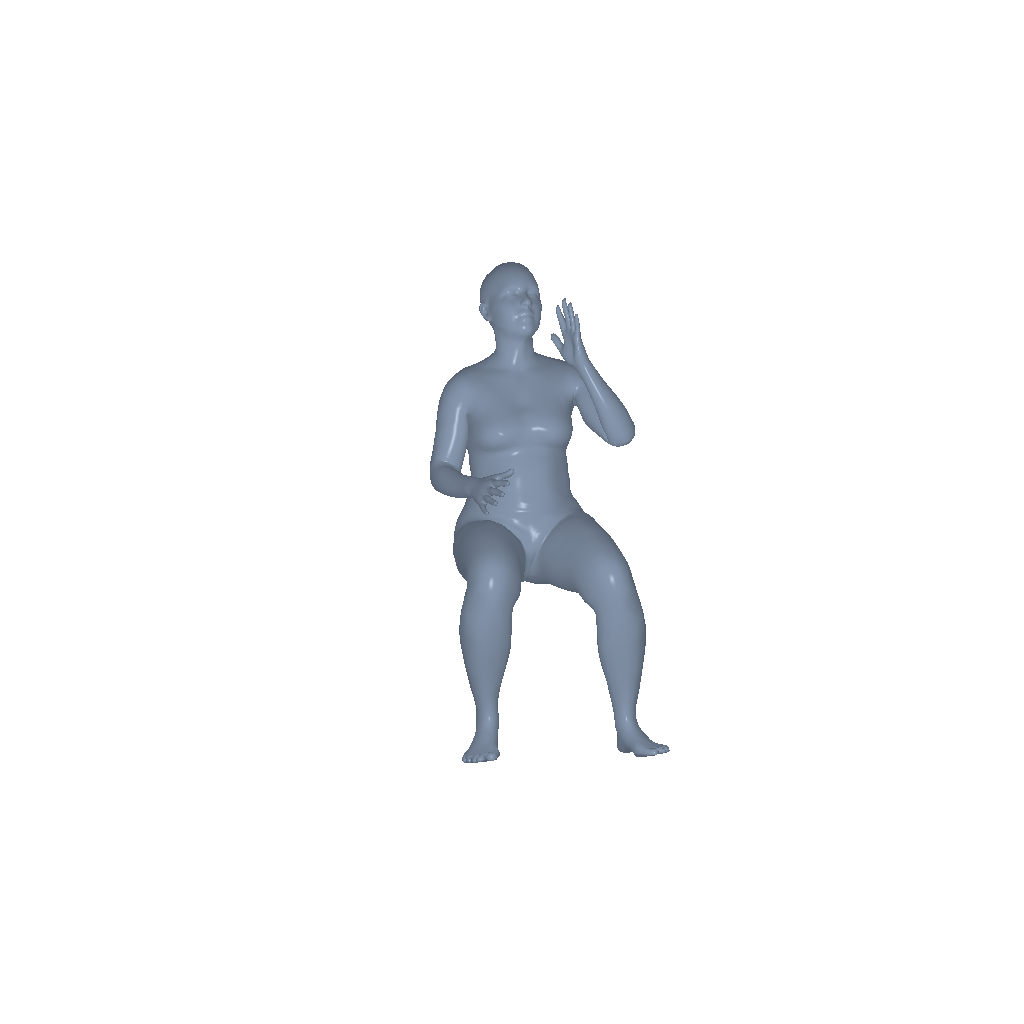

|
Throw |
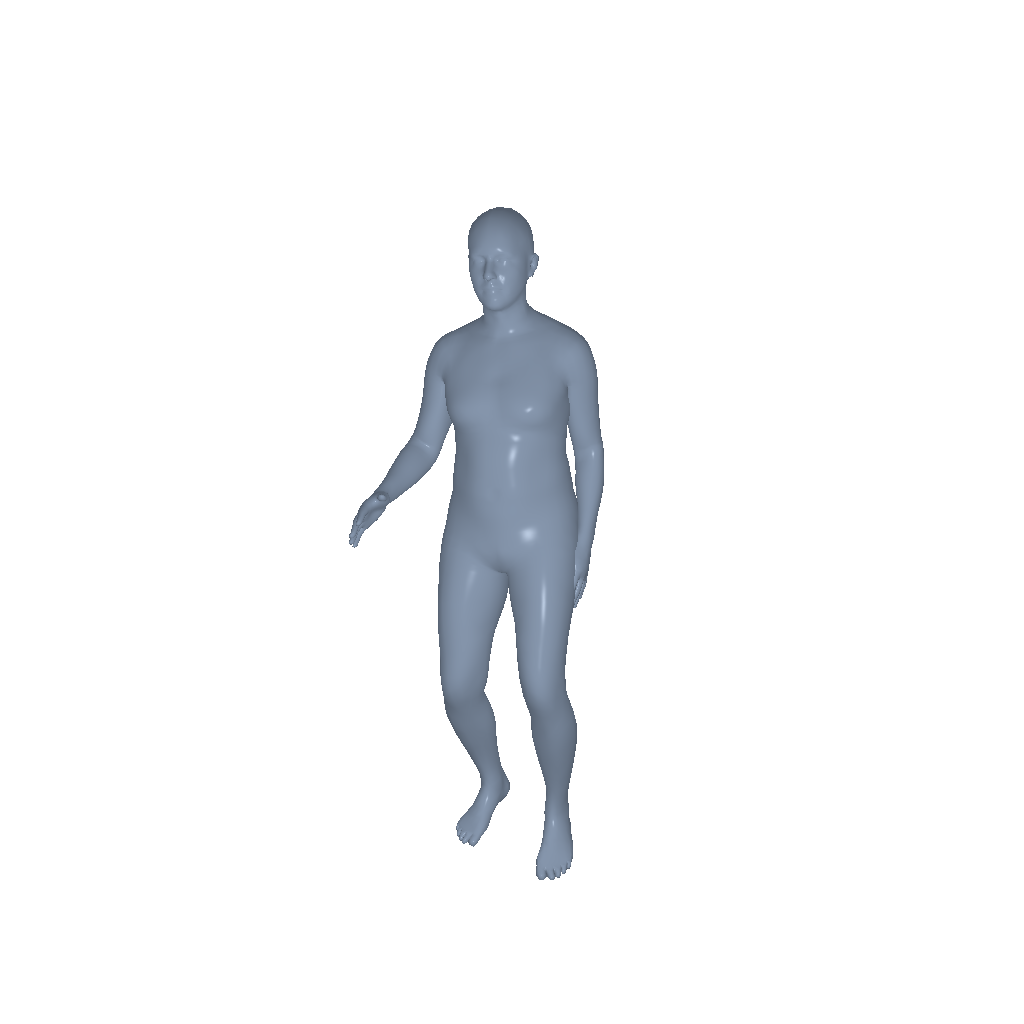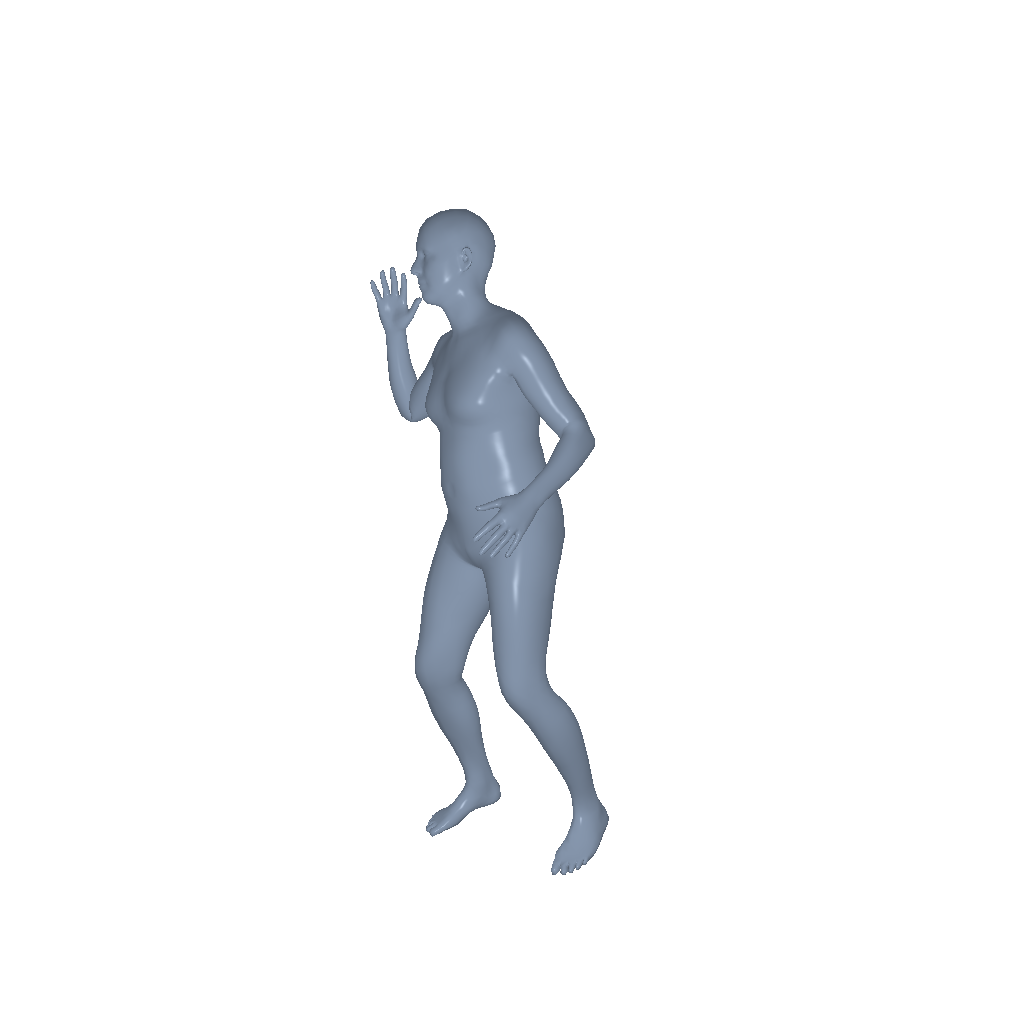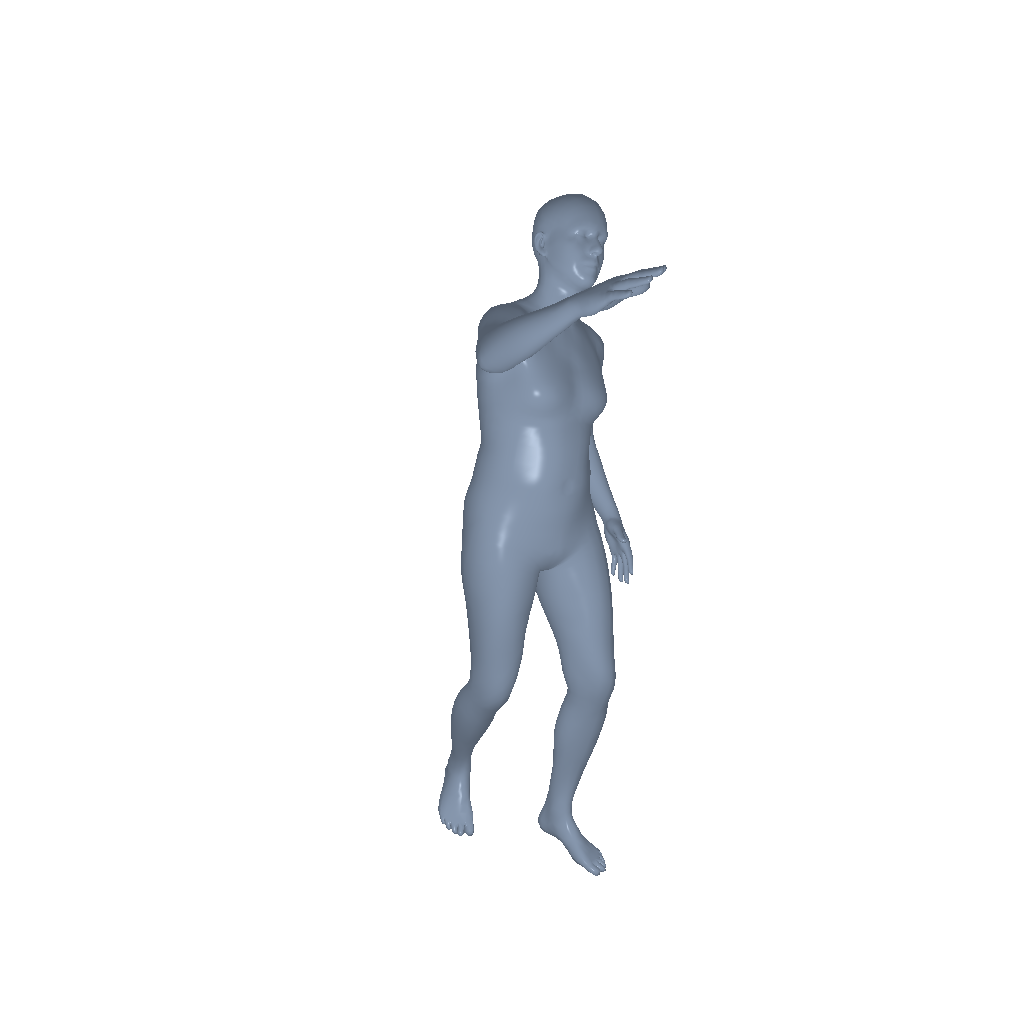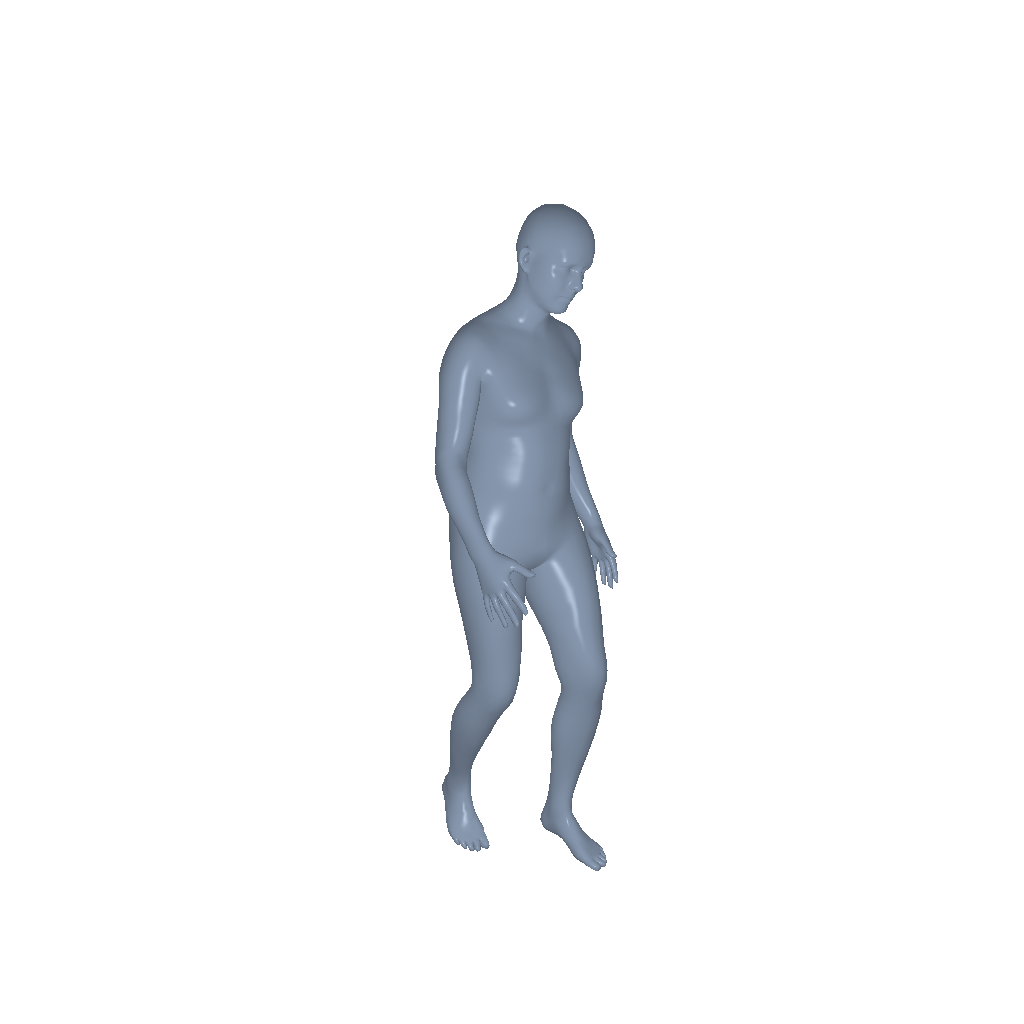

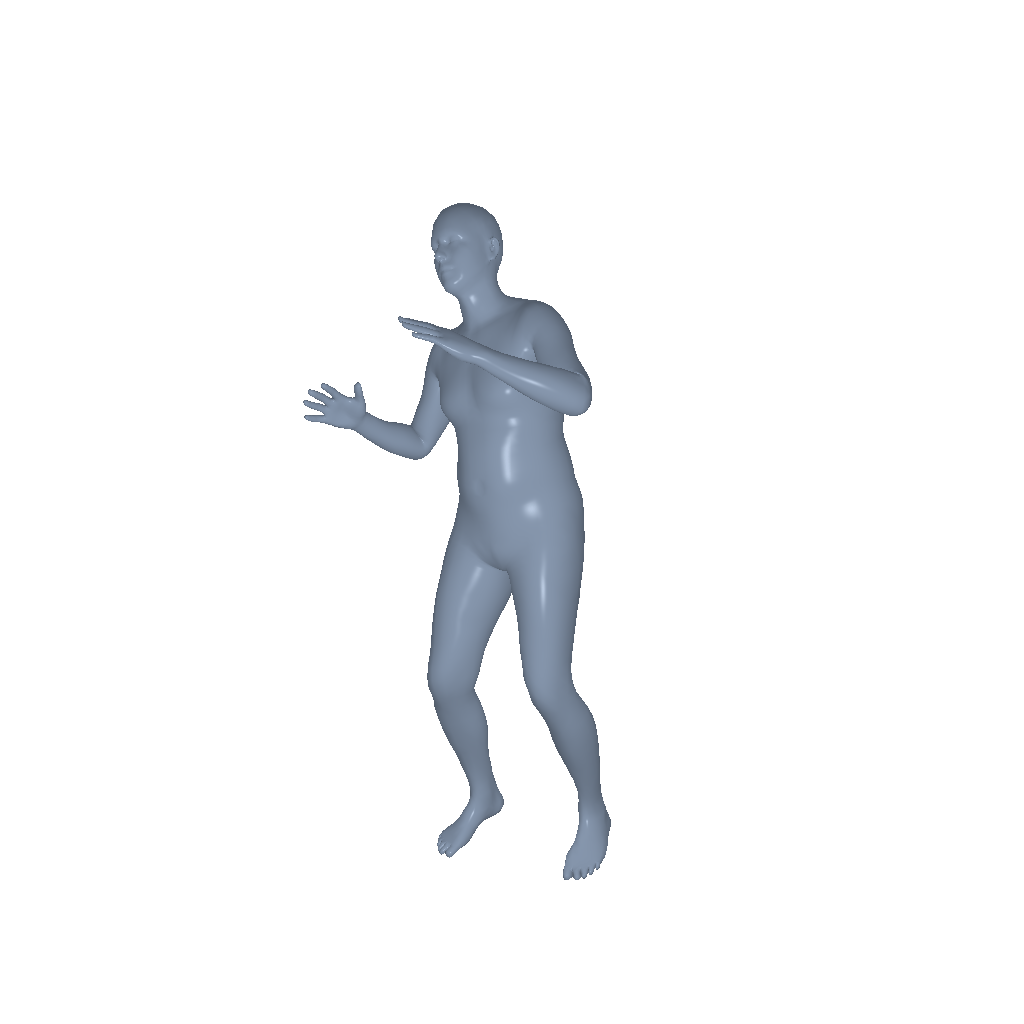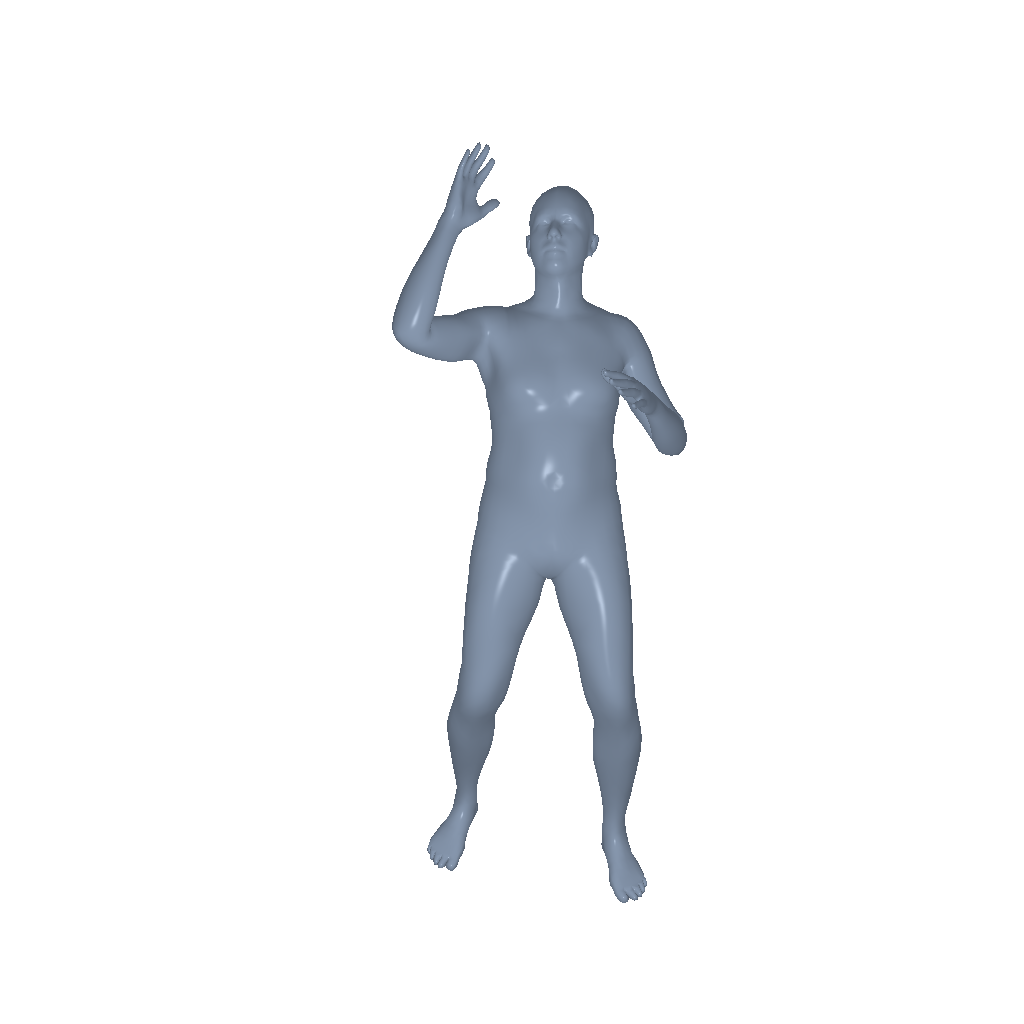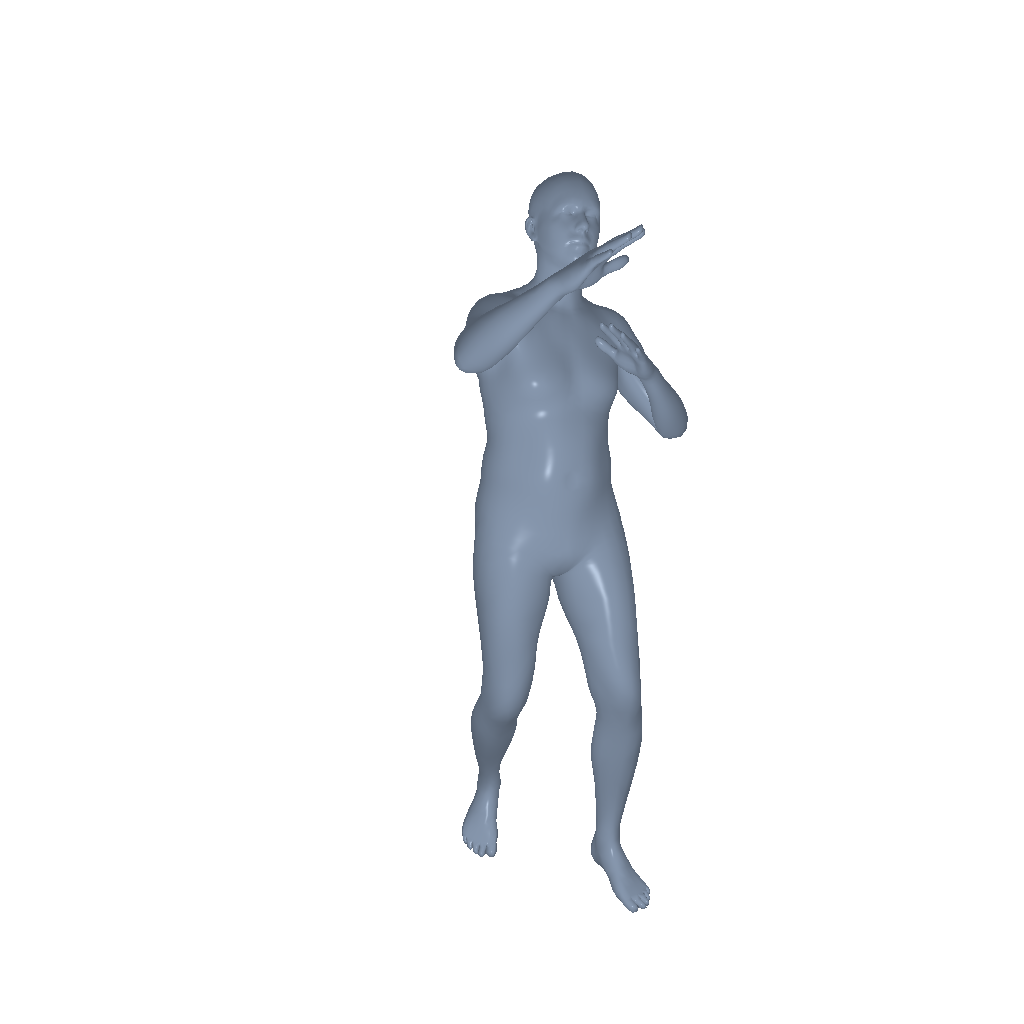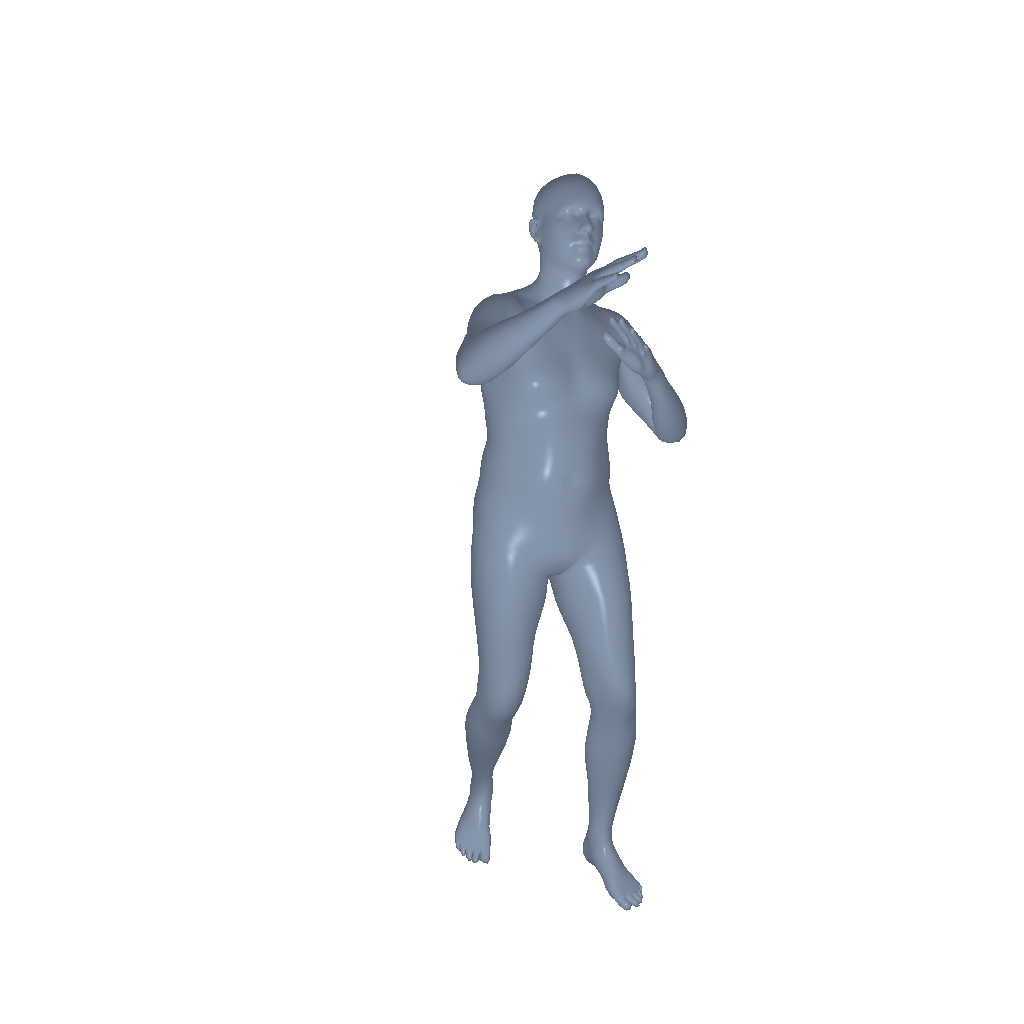
|
Jump |



|
Motions with Different Scales
Jump |



|
Acknowledgements |
*Q. Sun and A. Deng did this project during their internship at UoA